Why Multimodal Learning Matters
Multimodal learning is the next frontier in machine learning. It allows machines to combine different types of data to understand more than is possible from any one source.
Think of the example of understanding a scene in a play. As humans, our brains seamlessly integrate visual cues, auditory input, text, and prior knowledge. In a scene, we may see a waiter fall and drop a tray of drinks, we hear the crash of objects falling, we hear language spoken as someone reacts to the accident, and we read a caution sign saying the floor is wet. From this input, we easily conclude that the waiter slipped on the wet floor and dropped the drinks. This is due to our brains combining visual cues, auditory input, text, and prior knowledge. Without the combination of all of these inputs, we risk drawing the wrong conclusion about the scene. Auditory input alone might tell us an accident occurred, while visual cues may show a waiter slipping and drinks falling – but without reading the sign that says the floor is wet, we can’t fully understand why it happened.
Multimodal machine learning allows machines to perform a similar fusion of different data modalities, giving machines the ability to understand context, respond naturally, and make smart decisions in complex environments.
At Dstillery, we are experts at using AI to perform ad targeting. A powerful data modality in this space is user browsing behavior. The success of ad targeting campaigns is often measured by a conversion event performed online, such as purchasing a product or visiting a homepage. The journeys a user takes across the internet can be very predictive of whether they are likely to perform a particular online conversion or not.
For example, online retail sites visited by a consumer tells us the user’s style and the amount they may be willing to pay, and gives clues to demographic attributes such as gender and age. It is intuitive to see how this leads to useful features in an ad targeting campaign for a clothing brand. With the recent development in LLMs and generative AI, highly accurate text features can be generated for almost anything. This gives a second highly performing data modality we can use in our ad targeting campaigns.
We have built a modular, scalable multimodal architecture to integrate these data modalities and produce high-performing CTV ad targeting. Our patent-pending approach combines web behavioral features and text features to generate richer predictions, better personalization, and smarter automation of CTV ad targeting.
Our Approach: A Modular Multimodal Architecture for CTV Ad Targeting
Our CTV ad targeting system is built on a modular multimodal architecture that combines a foundation model with a lightweight mapping model. The foundation model is trained on large-scale web browsing behavior, while the mapping model enables us to extend that model’s capabilities to other data types — such as text — by projecting them into the same embedding space.
Foundation Model: Learning Behavioral Embeddings from Web Journeys
At the core of our system is a foundation model trained on web visitation sequences, producing what we call MOTI embeddings — short for Map Of The Internet. These embeddings are learned using self-supervised learning on billions of sequential website visits. The model is trained to predict the next website in a user’s browsing journey, allowing it to learn the behavioral patterns and intent behind web visits.
This results in a rich embedding space that captures user behavior across the open web — not just what sites users visit, but why and in what context. MOTI embeddings provide a strong signal for predicting future behavior, especially web-based conversions.
Mapping Model: Extending MOTI Embeddings to New Modalities
To enable multimodal learning, we train a mapping model that projects from text space into the MOTI embedding space. This allows us to represent any domain described by text — such as CTV content metadata — using the behavioral signal embedded in our foundation model.
We train this mapping model by aligning two modalities:
- MOTI embeddings for a large set of websites.
- LLM-generated keyword embeddings extracted from the same websites using generative AI.
By training a model to predict MOTI embeddings from LLM embeddings, we learn a cross-modal projection that allows us to map new text inputs (e.g., CTV parameters) into our MOTI space — effectively teaching the text modality to “speak the language” of web behavior.
Brand-Specific Models: Optimizing for Conversions
Clients often wish to drive outcomes measurable by web conversions — such as site visits, keyword searches, or product views. Since MOTI embeddings capture real behavioral intent, they serve as high-performing features for building client-specific models trained on conversion outcomes.
These models learn what types of behavior (in MOTI space) are most predictive of desired outcomes for each brand — allowing us to personalize targeting at scale.
CTV Targeting: Scoring Content Using Behavioral Signals
Once we’ve trained a brand-specific model in MOTI space, we can use it to score any other domain that can be described in text. For CTV ad targeting, we use generative AI to extract semantic features from content metadata — such as series, title, genre, language, rating, and channel.
These features are embedded using an LLM, then mapped into MOTI space via our mapping model. This allows us to use the brand’s web conversion model to score and rank CTV inventory based on how closely it aligns with high-performing web behaviors — creating a seamless link between behavioral intent and CTV content.
This architecture enables us to fuse two distinct data modalities — behavioral browsing data and structured text — through a shared representation space. It’s a powerful, scalable approach to multimodal learning: one that leverages foundation models, bridges across modalities, and delivers measurable performance in production systems. You can think of it as teaching the text modality to speak the behavioral language of MOTI embeddings, allowing both modalities to contribute meaningfully to targeting decisions.
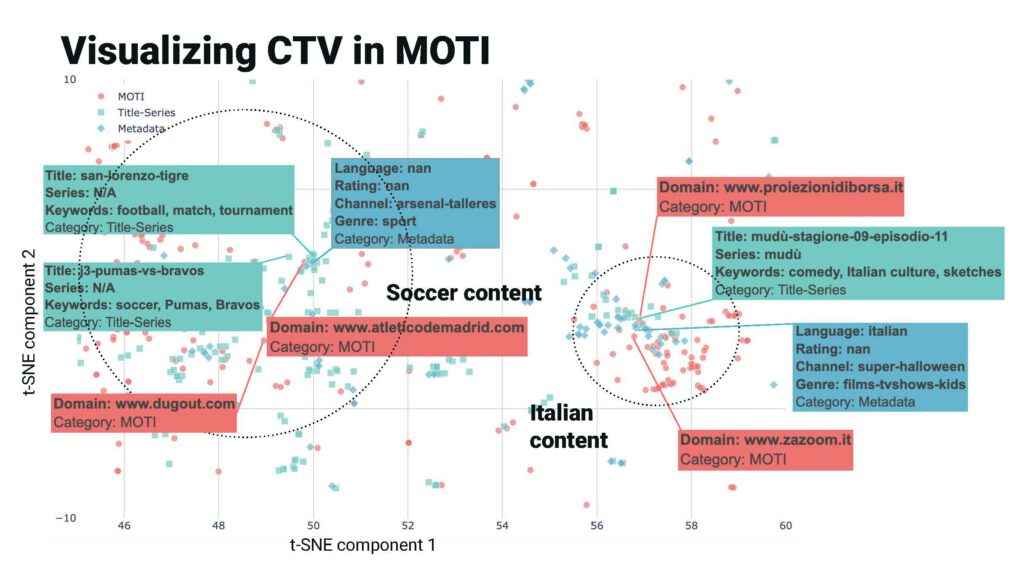
FIGURE: TSNE visualization of CTV attributes (series, title, language, rating, channel, genre) in the same space as websites in MOTI. As indicated by the left dotted circle, CTV attributes related to soccer, as well as soccer related domains are close by in the MOTI space. Another example indicated by the right dotted circle shows CTV attributes and nearby domains are related to Italian content.
A powerful, flexible approach to multimodal learning
Our CTV ad targeting solution is an effective and product-ready form of multimodal learning.
Scalable: Leveraging an existing foundation model trained on large amounts of streaming data allows the training of CTV models at scale. Training a model for each of our clients is fast and efficient.
Flexible: As text features from LLMs improve, or new CTV shows are aired, we can represent this new data in our multimodal model without retraining our large and computationally expensive foundation model.
Composable: As text features have emerged over the past couple of years, if there is a new data modality that is useful for ad targeting we can simply train a new mapping model and produce a multimodal solution with a new modality
Interpretable: Our solution is highly interpretable because we can query the joint representation space easily, giving us a clear understanding of the relationship between modalities
Results in the real world
Our modular multimodal targeting system has delivered strong, measurable performance across verticals, proving its value in real-world, ID-free environments.
Automotive Brand: Outperforming ID-Based Targeting
An automotive client sought to reach high-intent car shoppers using an ID-free CTV strategy. Using our modular multimodal architecture, we built a custom brand model for the campaign.
– The ID-free CTV model outperformed the client’s ID-based audience from day one, ultimately achieving a 98% higher video completion rate (VCR) by the end of the campaign.
– The model also delivered better cost efficiency, producing more CTV conversions at a lower cost per conversion (CPC), obtaining a CPC of $9.13.
– The client’s agency concluded that adding ID-free targeting alongside traditional ID-based models significantly expanded reach without sacrificing performance.
Kitchen Appliance Brand: Sustained Success Across CTV and Display
A kitchen appliance brand partnered with Dstillery to raise awareness for their new products using CTV and display media. They measured success using VCR and clickthrough rate (CTR) as KPIs.
– The campaign achieved a 94% average VCR on CTV beating the client benchmark of 70%.
– Display ads delivered a 0.14% CTR beating the 0.10% benchmark.
– Top-performing CTV channels included AT&T TV, Discovery Channel, and Food Network Kitchen — all aligned with high behavioral intent signals captured in our MOTI embeddings.
Multimodal AI for CTV: A Real-World Blueprint for Smarter Ad Targeting
Our solution is a framework for practical multimodal AI. When there are two complementary data sources and a unimodal foundation model exists for at least one of the modalities, a fast and efficient solution to multimodal machine learning is to train a model to learn a mapping from one modality to another. This produces an efficient multimodal solution that is interpretable and adaptable. You don’t need to train all modalities together from day one. Multimodal learning can be layered, modular, and immediately impactful. Multimodal learning isn’t just about giant models – It’s about combining signals to see more clearly and building systems that grow with your product.