Las Vegas hosted AdExchanger’s Programmatic AI event, and after two days of sessions and conversations, we left with a clearer picture of where the industry’s head is at and where the real work is happening.
The conversation has shifted
The most noticeable change from years past: nobody needed to be convinced that AI matters. The interesting debates were happening further upstream, around execution, differentiation, and what “useful AI” actually looks like in practice.
One phrase that kept surfacing was the shift from “human in the loop” to “human in the lead.” It reflects something we think about a lot at Dstillery: automation that accelerates doesn’t mean automation that replaces judgment. The organizations moving fastest aren’t chasing autonomy for its own sake. They’re embedding AI into the places where manual work creates the most drag.
There was also a lot of honest conversation about “pilot purgatory,” the gap between experimenting with AI tools and actually integrating them into scalable workflows. That gap is where many companies are still stuck, and it came up repeatedly as a more urgent challenge than any technological limitation.
Mark Jung on agents actually used in the wild
A highlight for us was Dstillery’s VP, Head of Product & AI, Mark Jung’s session, “Agents Built For Audience Buying Workflows… Actually Used In The Wild.” The framing was intentional: not a roadmap, not a demo of what’s coming, but a look at how agentic AI and Dstillery’s DS-1 platform are already running inside real audience-buying workflows today.
Mark walked through how Dstillery’s agentic AI advertising platform, DS-1, helps teams move faster on audience discovery, reduce activation timelines, and cut down on the manual operational work that tends to slow campaign execution. From audience creation to activation, the session showed how agentic AI can streamline workflows that traditionally take days into processes completed in minutes. The core argument: you don’t need fully autonomous systems or perfect industry standards to start generating real operational value. The work is happening now.
That landed well in the room, and it matched the tone of the broader conference. Less interest in flashy demos, more interest in what’s actually solving problems.
What we’re thinking about next
Consumer intent signals are getting more fragmented as AI assistants become a bigger part of how people discover and decide. That makes downstream behavioral modeling more important, specifically the kind that can work across fragmented signals. It’s a dynamic we’re watching closely.
There was also consistent emphasis on data quality and governance as AI takes on a larger operational role. The reality is that AI is only as strong as the data and systems behind it, and as automation scales, those foundations become even more important. For us at Dstillery, that’s where the real opportunity lies: building AI that’s not just fast, but reliable, scalable, and grounded in high-quality data.
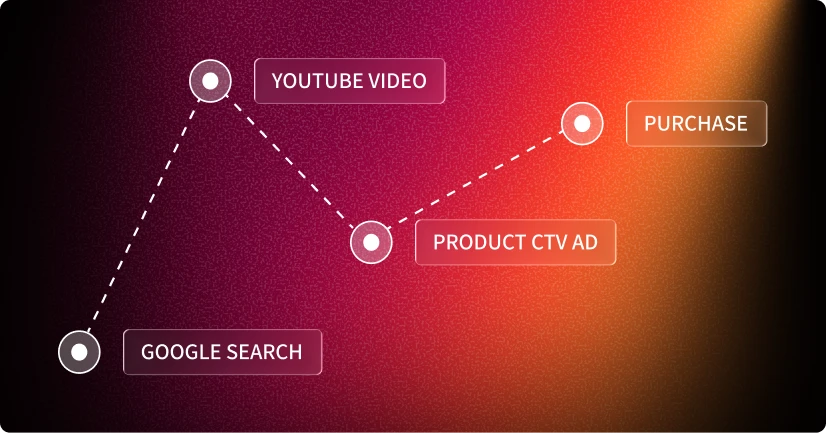
Picture this: You’re researching a new coffee maker. You Google “best espresso machines,” browse Williams-Sonoma’s website, watch a YouTube review, then see a CTV ad for Breville machines before finally making a purchase. Traditional ad targeting treats each of these touchpoints as isolated events. Multimodal AI sees them as one connected journey — and that’s revolutionizing how advertisers find and reach audiences.
The multimodal difference
While everyone’s been obsessed with Sora 2 putting their faces into videos, the advertising world has quietly been building something more practical: AI that can understand any type of data and apply those insights across any advertising channel.
“What you need is prediction based on behavioral data, and that’s why we wanted to use multimodal AI for prediction in digital ad targeting,” explains Melinda Han Williams, Chief Data Scientist at Dstillery. “By multimodal, we mean you can use different modalities of data — not just different sources. The difference between looking at words and what they mean and looking at behaviors and how you’ve seen them strung together as sequences in the past.”
Think of it like how humans naturally combine visual cues, sounds, text and context to understand a situation. When you see a waiter slip on a wet floor near a caution sign, your brain instantly processes multiple inputs to grasp the full story. Multimodal AI aims for that same fusion of understanding.
From brief to campaign in one model
Here’s where it gets interesting for advertisers. Instead of building separate models for search, display, CTV and everything else, multimodal AI creates one unified understanding that works everywhere.
“What sets multimodal AI apart is in its flexibility,” said Taejin In, Chief Product Officer at Dstillery. “Whether you have rich first-party data or just a basic campaign brief, multimodal AI can transform virtually any starting point into precise, actionable audiences.”
The system can take first-party data, CRM lists, search keywords, website URLs, or even just a paragraph describing your target audience. It then builds a model that can activate across user segments, contextual targeting, private marketplace deals and custom bidding algorithms — all from that single input.
This new way to approach targeting doesn’t just simplify workflows for overworked advertising professionals, but it also delivers superior outcomes. For example, an automotive brand using a curated CTV deal created by multimodal AI saw a much higher 98% video completion rate compared to traditional ID-based targeting, while an auto insurance company with direct response goals surprisingly discovered that contextual targeting outperformed 12 other tactics in their campaign, including traditional id-based lookalikes.
Why this matters now and in the future
Multimodal capabilities in digital ad targeting clearly provide a lot of value today – the application of more data to build more precise targeting, the ability to understand and reach audiences without relying solely on identifiers, and the ability to reduce vendor sprawl and simplify workflows.
However, something that might not be obvious is how multimodal AI is foundational for tomorrow’s AI agents and agentic advertising systems. “For agentic AI and advanced AI agents to truly deliver superior value, they need to understand all modes of data; you can’t do that without multimodality,” In explains, “Imagine if an AI agent can only reason from contextual signals. It would be missing behavioral signals which we all know are a much better predictor of intent”
With a multimodal foundation, these agentic AI systems and protocols will be able to understand multiple modes of data (web behavioral, CTV, in-app, search, user segment, evaluate and make decisions in a shared space, and interact with external systems all with different modalities.
The reality check
Multimodal AI isn’t magic. Success depends on having the right seed data and being willing to test and optimize. The most successful implementations happen when brands view it as a partnership, not a set-it-and-forget-it solution.
But for advertisers tired of managing dozens of disconnected models and tactics, multimodal AI offers a compelling alternative: one model that understands your audience across every signal and can activate that understanding anywhere in the programmatic ecosystem. In a world where consumer journeys zigzag across channels, that unified view isn’t just convenient — it’s essential.
Why the 2026 Big Game was more than halftime entertainment—it marked a turning point for AI in digital advertising.
For the first time since AI entered the mainstream with tools like ChatGPT in 2022, it wasn’t a sidebar in advertising — it was central to how brands approached the Super Bowl itself. Super Bowl LX reflected a broader shift in how agencies and brands are using AI to inform strategy, shape investment decisions, and decide when they’re ready to compete on marketing’s biggest stage.
1) AI Is No Longer About Tools—It’s a Defining Position
AI-driven decisioning wasn’t just influencing how ads were created, but which brands chose to show up at all.
That shift was especially evident in the rise of first-time Super Bowl advertisers. Performance-minded, growth-focused brands were willing to make high-stakes investments in live TV, using AI-backed insights to validate reach, relevance, and scale before committing to the biggest media buy of the year.
We want to give a shout-out to our TV advertising platform partner, Tatari, on securing and managing the ultimate in premium media placements for four first-time Super Bowl brand advertisers—Life360, Manscaped, Ro, and Tecovas—each making a deliberate bet on relevance, reach, and measurable outcomes. These brands didn’t simply “jump in” to the Super Bowl; they’ve been expanding beyond their original target markets and hero products. While AI may have played a role in their media strategies and ad targeting decisions, what’s clear is that the legacy brand-building playbook still has a valuable role, with agency partnerships and relationship currency more important than ever.
This theme of blending top performance and playing to win extended beyond the game itself. At Adweek House, these brands joined a panel led by Tatari’s SVP of Marketing, Amit Sharan. See the full story here: First-Time Playbooks for the Big Game
2) AI-Powered Targeting Is Now the Confidence Engine Behind Media Decisions
Super Bowl advertising has always been a media decision as much as a creative one. What changed this year was the confidence behind those decisions.
Rather than relying on broad demographics or legacy assumptions, advertisers leaned on AI-powered audience prediction and targeting to reduce risk and increase certainty. AI is no longer optimizing campaigns after launch—it’s shaping upfront investment decisions, giving brands the confidence to take bigger bets with expectations.
3) AI Is Embedded in Prediction and Engagement (Not Just Creation)
Every Super Bowl ad is ultimately a prediction: a bet on what audiences will remember, share, or act on. AI is accelerating that predictive capability across both media and messaging.
This year, that showed up through AI-forward brand narratives and competitive positioning that used AI as both a capability and a differentiator. The most effective advertisers weren’t chasing novelty—they were using AI to align insight, timing, and engagement to drive impact.
The Bigger Signal
Super Bowl LX made one thing clear: AI in advertising has moved beyond experimentation. It’s shaping confidence, precision, and prediction—helping marketers ensure the right messages reach the right audiences at the right moment.
Multimodal learning is the next frontier in machine learning. It allows machines to combine different types of data to understand more than is possible from any one source.
Think of the example of understanding a scene in a play. As humans, our brains seamlessly integrate visual cues, auditory input, text, and prior knowledge. In a scene, we may see a waiter fall and drop a tray of drinks, we hear the crash of objects falling, we hear language spoken as someone reacts to the accident, and we read a caution sign saying the floor is wet. From this input, we easily conclude that the waiter slipped on the wet floor and dropped the drinks. This is due to our brains combining visual cues, auditory input, text, and prior knowledge. Without the combination of all of these inputs, we risk drawing the wrong conclusion about the scene. Auditory input alone might tell us an accident occurred, while visual cues may show a waiter slipping and drinks falling – but without reading the sign that says the floor is wet, we can’t fully understand why it happened.
Multimodal machine learning allows machines to perform a similar fusion of different data modalities, giving machines the ability to understand context, respond naturally, and make smart decisions in complex environments.
At Dstillery, we are experts at using AI to perform ad targeting. A powerful data modality in this space is user browsing behavior. The success of ad targeting campaigns is often measured by a conversion event performed online, such as purchasing a product or visiting a homepage. The journeys a user takes across the internet can be very predictive of whether they are likely to perform a particular online conversion or not.
For example, online retail sites visited by a consumer tells us the user’s style and the amount they may be willing to pay, and gives clues to demographic attributes such as gender and age. It is intuitive to see how this leads to useful features in an ad targeting campaign for a clothing brand. With the recent development in LLMs and generative AI, highly accurate text features can be generated for almost anything. This gives a second highly performing data modality we can use in our ad targeting campaigns.
We have built a modular, scalable multimodal architecture to integrate these data modalities and produce high-performing CTV ad targeting. Our patent-pending approach combines web behavioral features and text features to generate richer predictions, better personalization, and smarter automation of CTV ad targeting.
Our Approach: A Modular Multimodal Architecture for CTV Ad Targeting
Our CTV ad targeting system is built on a modular multimodal architecture that combines a foundation model with a lightweight mapping model. The foundation model is trained on large-scale web browsing behavior, while the mapping model enables us to extend that model’s capabilities to other data types — such as text — by projecting them into the same embedding space.
Foundation Model: Learning Behavioral Embeddings from Web Journeys
At the core of our system is a foundation model trained on web visitation sequences, producing what we call MOTI embeddings — short forMap Of The Internet. These embeddings are learned using self-supervised learning on billions of sequential website visits. The model is trained to predict the next website in a user’s browsing journey, allowing it to learn the behavioral patterns and intent behind web visits.
This results in a rich embedding space that captures user behavior across the open web — not just what sites users visit, but why and in what context. MOTI embeddings provide a strong signal for predicting future behavior, especially web-based conversions.
Mapping Model: Extending MOTI Embeddings to New Modalities
To enable multimodal learning, we train a mapping model that projects from text space into the MOTI embedding space. This allows us to represent any domain described by text — such as CTV content metadata — using the behavioral signal embedded in our foundation model.
We train this mapping model by aligning two modalities:
MOTI embeddings for a large set of websites.
LLM-generated keyword embeddings extracted from the same websites using generative AI.
By training a model to predict MOTI embeddings from LLM embeddings, we learn a cross-modal projection that allows us to map new text inputs (e.g., CTV parameters) into our MOTI space — effectively teaching the text modality to “speak the language” of web behavior.
Brand-Specific Models: Optimizing for Conversions
Clients often wish to drive outcomes measurable by web conversions — such as site visits, keyword searches, or product views. Since MOTI embeddings capture real behavioral intent, they serve as high-performing features for building client-specific models trained on conversion outcomes.
These models learn what types of behavior (in MOTI space) are most predictive of desired outcomes for each brand — allowing us to personalize targeting at scale.
CTV Targeting: Scoring Content Using Behavioral Signals
Once we’ve trained a brand-specific model in MOTI space, we can use it to score any other domain that can be described in text. For CTV ad targeting, we use generative AI to extract semantic features from content metadata — such as series, title, genre, language, rating, and channel.
These features are embedded using an LLM, then mapped into MOTI space via our mapping model. This allows us to use the brand’s web conversion model to score and rank CTV inventory based on how closely it aligns with high-performing web behaviors — creating a seamless link between behavioral intent and CTV content.
This architecture enables us to fuse two distinct data modalities — behavioral browsing data and structured text — through a shared representation space. It’s a powerful, scalable approach to multimodal learning: one that leverages foundation models, bridges across modalities, and delivers measurable performance in production systems. You can think of it as teaching the text modality to speak the behavioral language of MOTI embeddings, allowing both modalities to contribute meaningfully to targeting decisions.
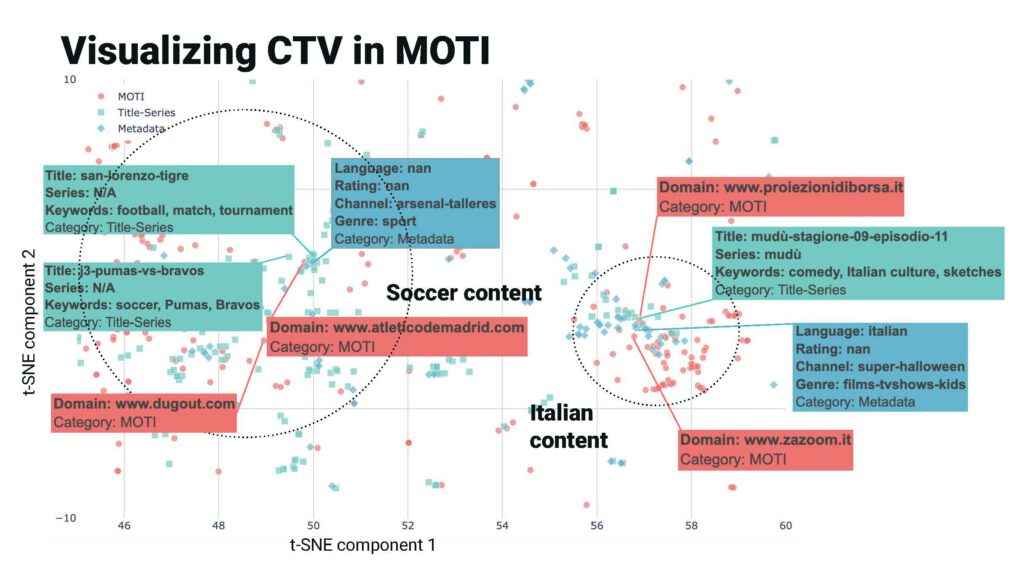
FIGURE: TSNE visualization of CTV attributes (series, title, language, rating, channel, genre) in the same space as websites in MOTI. As indicated by the left dotted circle, CTV attributes related to soccer, as well as soccer related domains are close by in the MOTI space. Another example indicated by the right dotted circle shows CTV attributes and nearby domains are related to Italian content.
A powerful, flexible approach to multimodal learning
Scalable: Leveraging an existing foundation model trained on large amounts of streaming data allows the training of CTV models at scale. Training a model for each of our clients is fast and efficient.
Flexible: As text features from LLMs improve, or new CTV shows are aired, we can represent this new data in our multimodal model without retraining our large and computationally expensive foundation model.
Composable: As text features have emerged over the past couple of years, if there is a new data modality that is useful for ad targeting we can simply train a new mapping model and produce a multimodal solution with a new modality
Interpretable: Our solution is highly interpretable because we can query the joint representation space easily, giving us a clear understanding of the relationship between modalities
Results in the real world
Our modular multimodal targeting system has delivered strong, measurable performance across verticals, proving its value in real-world, ID-free environments.
An automotive client sought to reach high-intent car shoppers using an ID-free CTV strategy. Using our modular multimodal architecture, we built a custom brand model for the campaign.
– The ID-free CTV model outperformed the client’s ID-based audience from day one, ultimately achieving a 98% higher video completion rate (VCR) by the end of the campaign. – The model also delivered better cost efficiency, producing more CTV conversions at a lower cost per conversion (CPC), obtaining a CPC of $9.13. – The client’s agency concluded that adding ID-free targeting alongside traditional ID-based models significantly expanded reach without sacrificing performance.
Kitchen Appliance Brand: Sustained Success Across CTV and Display
A kitchen appliance brand partnered with Dstillery to raise awareness for their new products using CTV and display media. They measured success using VCR and clickthrough rate (CTR) as KPIs.
– The campaign achieved a 94% average VCR on CTV beating the client benchmark of 70%. – Display ads delivered a 0.14% CTR beating the 0.10% benchmark. – Top-performing CTV channels included AT&T TV, Discovery Channel, and Food Network Kitchen — all aligned with high behavioral intent signals captured in our MOTI embeddings.
Multimodal AI for CTV: A Real-World Blueprint for Smarter Ad Targeting
Our solution is a framework for practical multimodal AI. When there are two complementary data sources and a unimodal foundation model exists for at least one of the modalities, a fast and efficient solution to multimodal machine learning is to train a model to learn a mapping from one modality to another. This produces an efficient multimodal solution that is interpretable and adaptable. You don’t need to train all modalities together from day one. Multimodal learning can be layered, modular, and immediately impactful. Multimodal learning isn’t just about giant models – It’s about combining signals to see more clearly and building systems that grow with your product.
Want to hear fresh perspectives on Data Analytics and Data Science while staying on top of industry trends? Check out the Who’s Your Data Podcast, hosted by Gilad Barash, Dstillery’s VP of Analytics.
Listen as Gilad gets candid with interesting industry leaders – from thoughts on data science career paths to inclusivity and representation in tech – nothing is off-limits.
If you’re interested in data, analytics, or curious about how diversity and inclusiveness play a role in combating bias in data and tech, this podcast is for you! Listen on Apple Podcasts & Spotify today.